IllusionVQA
IllusionVQA
The advent of Vision Language Models (VLM) has allowed researchers to investigate the visual understanding of a neural network using natural language. Beyond object classification and detection, VLMs are capable of visual comprehension and common-sense reasoning. This naturally led to the question: How do VLMs respond when the image itself is inherently unreasonable?
To this end, we present
IllusionVQA
: a diverse dataset of challenging optical illusions and
hard-to-interpret scenes to test the capability of
VLMs in two distinct multiple-choice
Visual Question Answering tasks - comprehension and soft
localization.
GPT4V, the best performing VLMs, achieves 62.99% accuracy (4-shot) on the comprehension task and 49.7% on the localization task (4-shot and Chain-of-Thought). Human evaluation reveals that humans achieve 91.03% and 100% accuracy in comprehension and localization. We discover that In-Context Learning (ICL) and Chain-of-Thought reasoning substantially degrade the performance of Gemini-Pro on the localization task. Tangentially, we discover a potential weakness in the ICL capabilities of VLMs: they fail to locate optical illusions even when the correct answer is in the context window as a few-shot example.
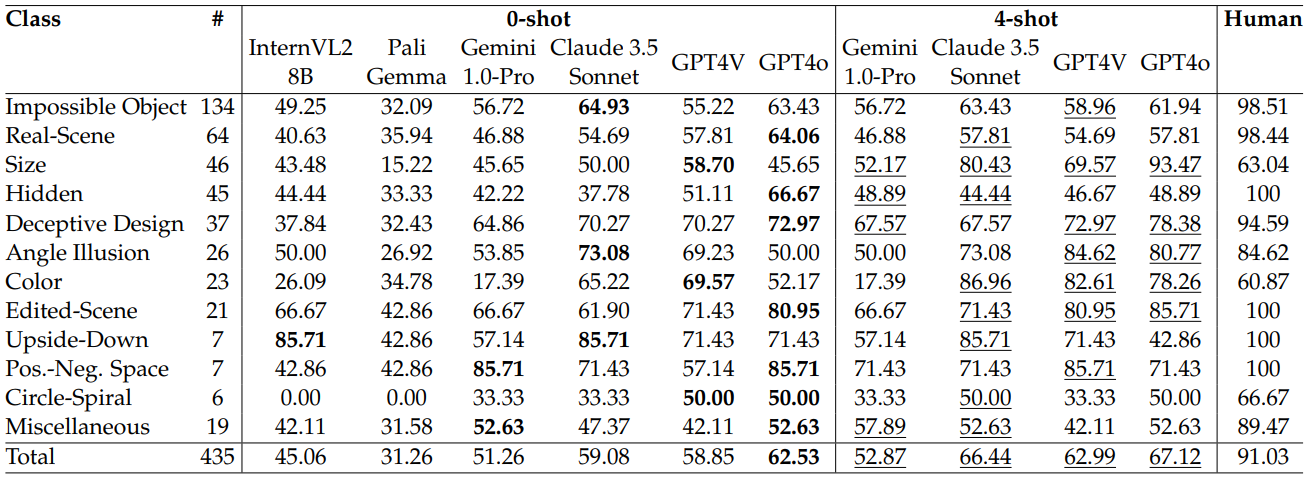
| # | Model | Source | Date | ALL |
Impossible Object |
Real Scene |
Size | Hidden |
Deceptive Design |
Angle Illusion |
Color |
Edited Scene |
Upside Down |
Pos.-Neg Space |
Circle Spiral |
Miscellaneous |
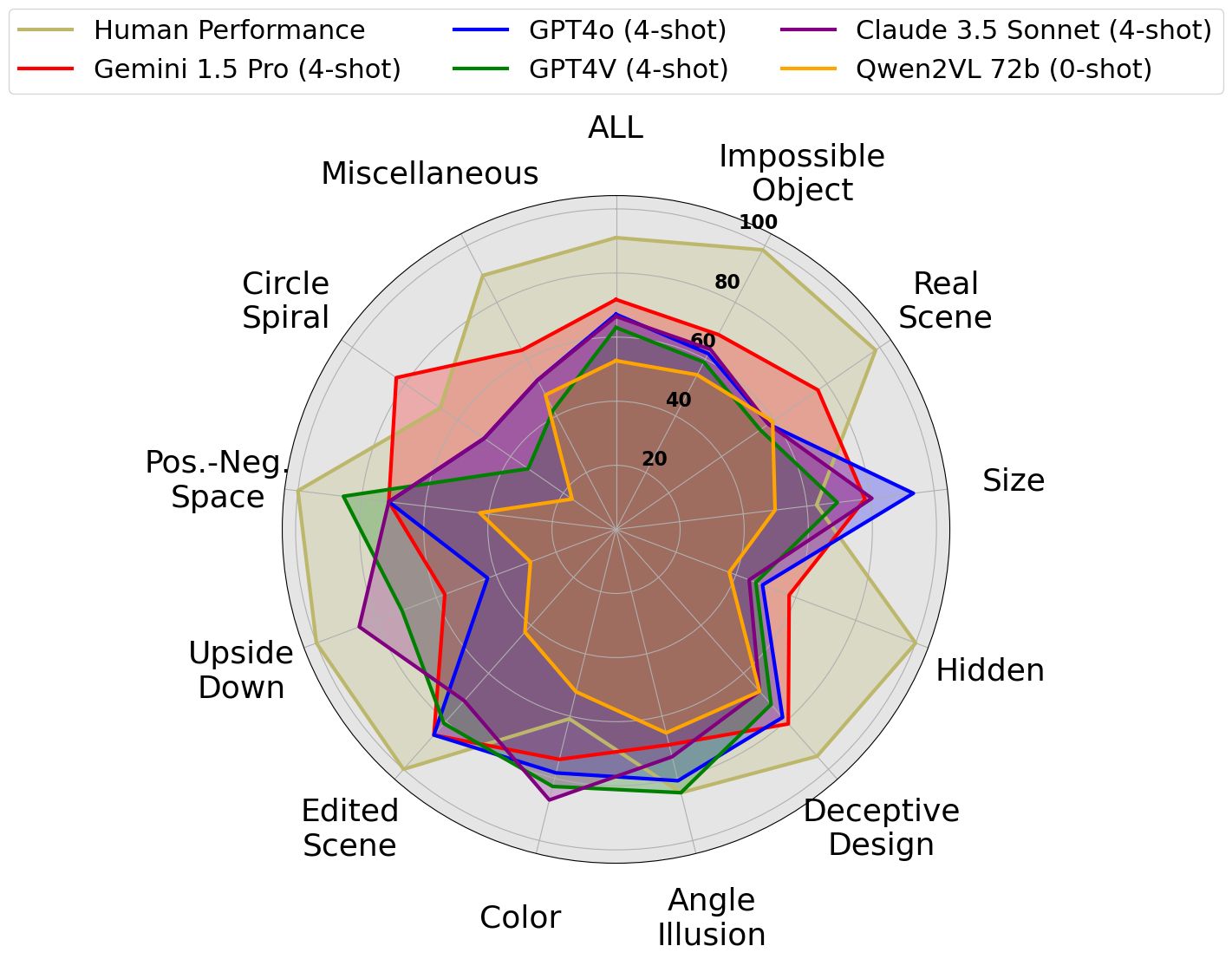
| - | Human Performance | Link | 2024-02-25 | 91.03 | 98.51 | 98.44 | 63.04 | 100 | 94.59 | 84.62 | 60.87 | 100 | 100 | 100 | 66.67 | 89.47 |
| 1 | Gemini-1.5-Pro (4-shot) | Link | 2024-08-31 | 71.72 | 68.66 | 76.56 | 78.26 | 57.78 | 81.08 | 69.23 | 73.91 | 85.71 | 57.14 | 71.43 | 83.33 | 63.16 |
| 2 | o4-mini (0-shot) | Link | 2025-04-25 | 71.49 | 71.64 | 64.06 | 78.26 | 57.77 | 78.39 | 88.46 | 82.61 | 80.95 | 57.14 | 71.43 | 50.00 | 36.84 |
| 3 | gpt-4.1 (0 shot) | Link | 2025-04-25 | 68.74 | 69.40 | 67.19 | 71.74 | 62.22 | 86.48 | 69.23 | 73.91 | 80.95 | 42.85 | 71.43 | 33.33 | 57.89 |
| - | GPT4o (4-shot) | Link | 2024-07-28 | 67.12 | 61.94 | 57.81 | 93.47 | 48.89 | 78.38 | 80.77 | 78.26 | 85.71 | 42.86 | 71.43 | 50.00 | 52.63 |
| Claude 3.5 Sonnet (4-shot) | Link | 2024-07-28 | 66.44 | 63.43 | 57.81 | 80.43 | 44.44 | 67.57 | 73.08 | 86.96 | 71.43 | 85.71 | 71.43 | 50.00 | 52.63 | |
| 4 | Gemini-1.5-Pro (0-shot) | Link | 2024-08-31 | 65.98 | 70.90 | 70.31 | 58.70 | 53.33 | 70.27 | 57.69 | 47.83 | 85.71 | 57.14 | 71.43 | 66.67 | 68.42 |
| 5 | GPT4V (4-shot) | Link | 2024-02-25 | 62.99 | 58.96 | 54.69 | 69.57 | 46.67 | 72.97 | 84.62 | 82.61 | 80.95 | 71.43 | 85.71 | 33.33 | 42.11 |
| 6 | GPT4o (0-shot) | Link | 2024-07-28 | 62.53 | 63.43 | 64.06 | 45.65 | 66.67 | 72.97 | 50.00 | 52.17 | 80.95 | 71.42 | 85.71 | 50.00 | 52.63 |
| 7 | Gemini 1.5 Flash (4-shot) | Link | 2024-08-31 | 59.31 | 63.43 | 57.81 | 69.57 | 48.89 | 78.38 | 7.69 | 43.48 | 80.95 | 71.43 | 71.43 | 33.33 | 63.16 |
| 8 | Claude 3.5 Sonnet (0-shot) | Link | 2024-07-28 | 59.08 | 64.93 | 54.69 | 50.00 | 37.78 | 70.27 | 73.08 | 65.22 | 61.90 | 85.71 | 71.43 | 33.33 | 47.37 |
| 9 | GPT4V (0-shot) | Link | 2024-02-25 | 58.85 | 55.22 | 57.81 | 58.70 | 51.11 | 70.27 | 69.23 | 69.57 | 71.43 | 71.43 | 57.14 | 50 | 42.11 |
| 10 | Gemini 1.5 Flash (0-shot) | Link | 2024-08-31 | 54.02 | 62.69 | 56.25 | 36.96 | 48.89 | 64.86 | 30.77 | 21.74 | 66.67 | 71.43 | 57.14 | 50.00 | 68.42 |
| 11 | Gemini-1-Pro (4-shot) | Link | 2024-02-25 | 52.87 | 56.72 | 46.88 | 52.17 | 48.89 | 67.56 | 50 | 17.39 | 66.67 | 57.14 | 71.43 | 33.33 | 57.89 |
| 12 | Qwen2-VL 72b (0-shot) | Link | 2024-09-22 | 52.64 | 54.48 | 59.38 | 50.00 | 37.78 | 67.57 | 65.39 | 52.17 | 42.86 | 28.57 | 42.86 | 16.67 | 47.37 |
| 13 | Gemini-1-Pro (0-shot) | Link | 2024-02-25 | 51.26 | 56.72 | 46.88 | 45.65 | 42.22 | 64.86 | 53.85 | 17.39 | 66.67 | 57.14 | 85.71 | 33.33 | 52.63 |
| 14 | LlaVa Onevision Qwen2 7b (0-shot) | Link | 2024-09-20 | 49.66 | 51.49 | 48.44 | 28.26 | 48.89 | 56.76 | 53.85 | 47.83 | 52.38 | 71.43 | 42.86 | 33.33 | 73.68 |
| 15 | Llama 3.2 90B Vision-Instruct (0-shot) | Link | 2024-10-06 | 48.74 | 50.74 | 46.87 | 43.48 | 42.22 | 64.86 | 57.69 | 21.74 | 66.67 | 28.57 | 71.43 | 16.67 | 47.37 |
| 16 | InternVL2-8B (0-shot) | Link | 2024-07-28 | 45.06 | 49.25 | 40.63 | 43.48 | 44.44 | 37.84 | 50.00 | 26.09 | 66.67 | 85.71 | 42.86 | 0.00 | 42.11 |
| 17 | Phi 3.5 Vision-4.2B (0-shot) | Link | 2024-08-21 | 41.38 | 43.28 | 28.13 | 56.52 | 31.11 | 56.76 | 38.46 | 21.74 | 61.9 | 71.43 | 42.86 | 16.67 | 31.58 |
| 18 | Llama 3.2 Vision Instruct-11B | Link | 2024-09-30 | 41.00 | 44.78 | 46.88 | 28.26 | 40.00 | 27.03 | 42.31 | 30.43 | 42.86 | 71.43 | 42.86 | 50.00 | 47.37 |
| 19 | LLaVa 1.5 (0-shot) | Link | 2024-02-25 | 40 | 43.28 | 42.19 | 19.57 | 42.22 | 43.24 | 38.46 | 26.09 | 61.90 | 71.43 | 42.86 | 0.00 | 42.11 |
| 20 | Cog (0-shot) | Link | 2024-02-25 | 38.16 | 44.03 | 34.38 | 13.04 | 42.22 | 45.95 | 30.77 | 30.43 | 42.86 | 71.43 | 71.43 | 16.67 | 42.11 |
| 21 | Phi 3.5 Vision-4.2B (4-shot) | Link | 2024-08-26 | 34.71 | 41.79 | 26.56 | 36.95 | 22.22 | 40.54 | 23.07 | 8.70 | 52.38 | 42.86 | 57.14 | 33.33 | 42.11 |
| 22 | I-BLIP (0-shot) | Link | 2024-02-25 | 34.25 | 34.22 | 26.56 | 26.09 | 44.44 | 37.84 | 30.77 | 30.43 | 42.86 | 42.86 | 57.41 | 33.33 | 36.84 |
| 23 | Pali Gemma (0-shot) | Link | 2024-07-28 | 31.26 | 32.09 | 35.94 | 15.22 | 33.33 | 32.43 | 26.92 | 34.78 | 42.86 | 42.86 | 42.86 | 0.00 | 31.58 |
The columns represent the different types of illusions in the dataset.
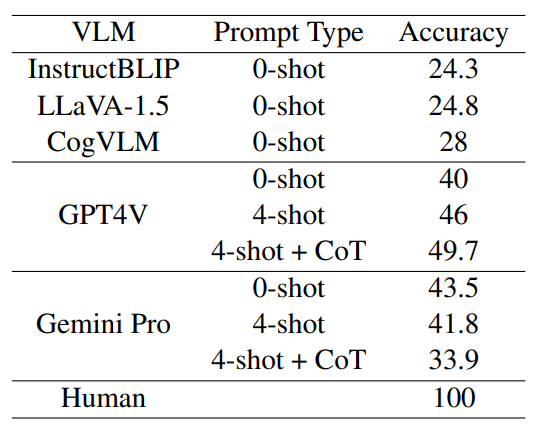
| # | Model | Source | Date | Accuracy |
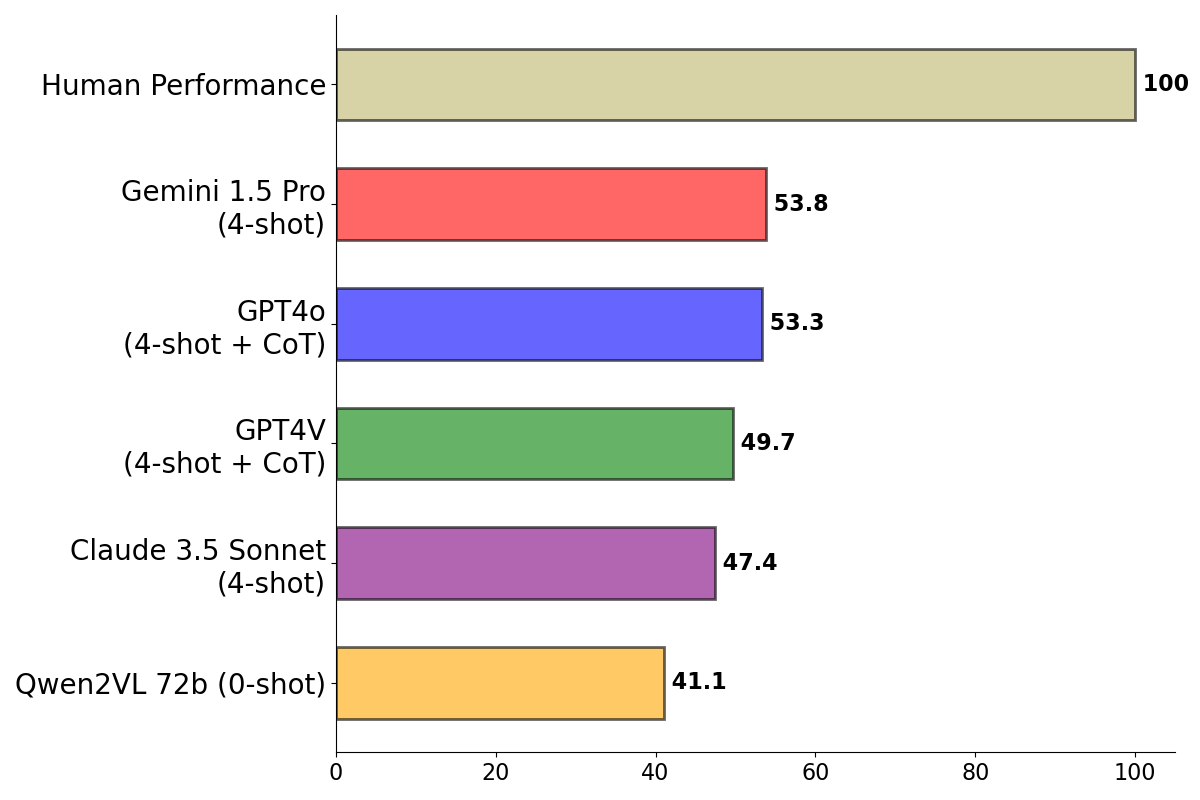
| - | Human Performance* | Link | 2024-02-25 | 100 |
| 1 | Gemini-1.5-Pro (4-shot) | Link | 2024-08-16 | 53.8 |
| 2 | GPT4o (4-shot + CoT) | Link | 2024-08-16 | 53.3 |
| 3 | Gemini-1.5-Pro (4-shot + CoT) | Link | 2024-08-31 | 50.7 |
| 4 | Gemini-1.5-Flash (4-shot) | Link | 2024-08-31 | 49.8 |
| 5 | GPT4V (4-shot + CoT) | Link | 2024-02-25 | 49.7 |
| 6 | GPT4o (4-shot) | Link | 2024-08-16 | 49.1 |
| 7 | Claude 3.5 Sonnet (4-shot) | Link | 2024-08-16 | 47.4 |
| 8 | Gemini-1.5-Pro (0-shot) | Link | 2024-08-31 | 47.3 |
| 9 | GPT4V (4-shot) | Link | 2024-02-25 | 46 |
| 10 | Claude 3.5 Sonnet (0-shot) | Link | 2024-08-16 | 45.9 |
| 11 | Gemini-1.5-Flash (4-shot + CoT) | Link | 2024-08-31 | 45.9 |
| 12 | GPT4o (0-shot) | Link | 2024-08-16 | 45 |
| 13 | Gemini 1.0 Pro (0-shot) | Link | 2024-02-15 | 43.5 |
| 14 | Gemini-1.5-Flash (0-shot) | Link | 2024-08-31 | 42.4 |
| 15 | Gemini 1.0 Pro (4-shot) | Link | 2024-02-15 | 41.8 |
| 16 | Qwen2-VL 72b (0-shot) | Link | 2024-09-23 | 41.1 |
| 17 | GPT4V (0-shot) | Link | 2024-02-25 | 40 |
| 18 | Claude 3.5 Sonnet (4-shot + CoT) | Link | 2024-08-27 | 39.5 |
| 19 | LlaVa Onevision Qwen2 7b (0-shot) | Link | 2024-09-20 | 37.3 |
| 20 | Gemini 1.0 Pro (4-shot + CoT) | Link | 2024-02-25 | 33.9 |
| 21 | Llama 3.2 Vision Instruct-11B | Link | 2024-09-30 | 33.6 |
| 22 | InternVL2-8B (0-shot) | Link | 2024-08-16 | 28.3 |
| 23 | CogVLM (0-shot) | Link | 2024-02-15 | 28 |
| 24 | Phi 3.5 Vision-4.2B (4-shot + CoT) | Link | 2024-08-26 | 27.0 |
| 25 | Phi 3.5 Vision-4.2B (4-shot) | Link | 2024-08-26 | 24.9 |
| 26 | Phi 3.5 Vision-4.2B (0-shot) | Link | 2024-08-21 | 24.9 |
| 27 | LLaVA-1.5 (0-shot) | Link | 2024-02-15 | 24.8 |
| 28 | InstructBLIP (0-shot) | Link | 2024-02-15 | 24.3 |
*Measured on a subset of 200 samples.
🚨 To submit your results to the leaderboard, please send to this email with your result json files.
🚨 For more submission details, please refer to this link
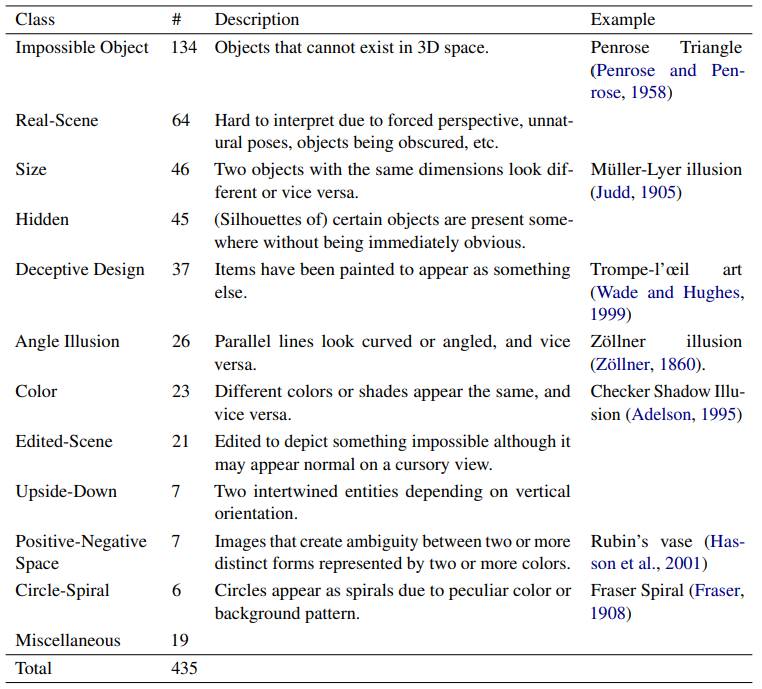
IllusionVQA Dataset
IllusionVQA is a Visual Question
Answering (VQA) dataset with two sub-tasks. The first task
tests comprehension on 435 instances in 12 optical illusion
categories. Each instance consists of an image with an optical
illusion, a question, and 3 to 6 options, one of which is the
correct answer. We refer to this task as
IllusionVQA-Comprehension. The second task tests how well VLMs can differentiate
geometrically impossible objects from ordinary objects when two
objects are presented side by side. The task consists of
1000 instances following a similar format to the first
task. We refer to this task as
IllusionVQA-Soft-Localization
.
 IllusionVQA-Comprehension
IllusionVQA-Comprehension
 IllusionVQA-Comprehension
IllusionVQA-Comprehension
One examples for each type of illusion in
IllusionVQA-Comprehension











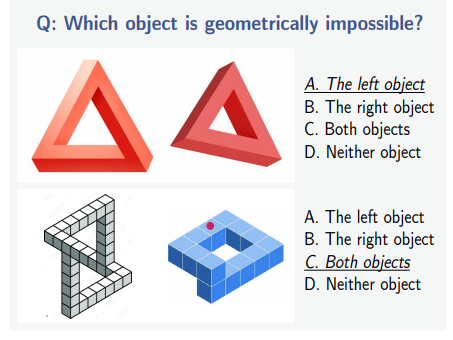
Samples questions from
IllusionVQA-Comprehension



Samples questions from
IllusionVQA-Soft-Localization
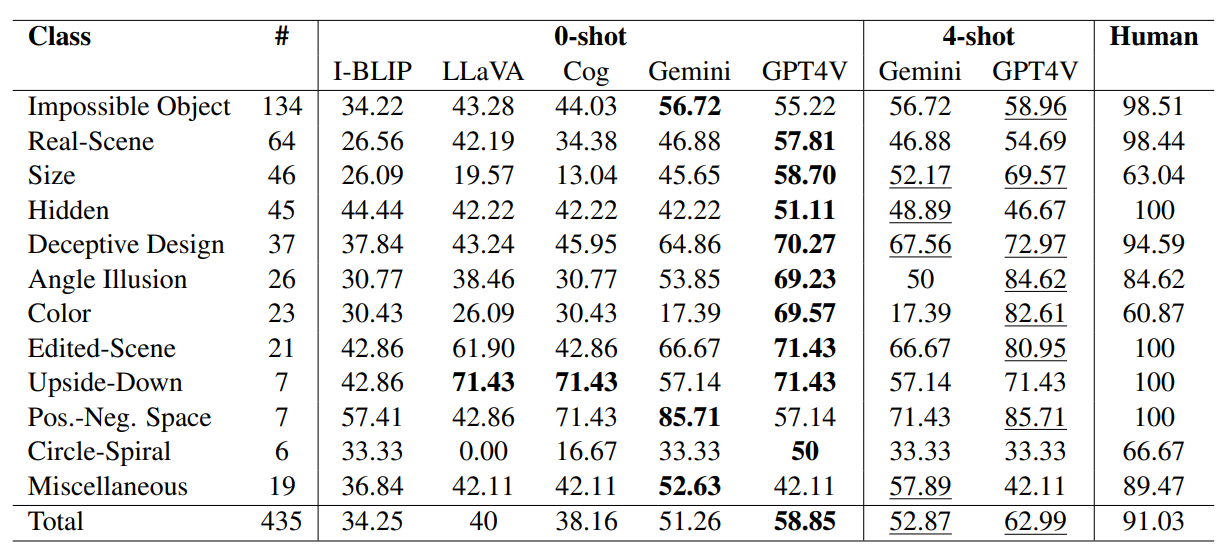 IllusionVQA-Comprehension
task. Categories where accuracy has improved using 4-shot
prompting are underlined. Human performance refers to the
aggregated performance based on the majority vote of three
human evaluators.
IllusionVQA-Comprehension
task. Categories where accuracy has improved using 4-shot
prompting are underlined. Human performance refers to the
aggregated performance based on the majority vote of three
human evaluators.
 IllusionVQA-Soft-Localization
task. Human performance denotes the majority vote performance
on three human evaluators on 200 randomly picked instances.
IllusionVQA-Soft-Localization
task. Human performance denotes the majority vote performance
on three human evaluators on 200 randomly picked instances.
 IllusionVQA-Comprehension
task. Categories where accuracy has improved using 4-shot
prompting are underlined. Human performance refers to the
aggregated performance based on the majority vote of three
human evaluators.
IllusionVQA-Comprehension
task. Categories where accuracy has improved using 4-shot
prompting are underlined. Human performance refers to the
aggregated performance based on the majority vote of three
human evaluators.
Check out the huggingface dataset viewer for IllusionVQA-Comprehension & IllusionVQA-Soft-Localization!
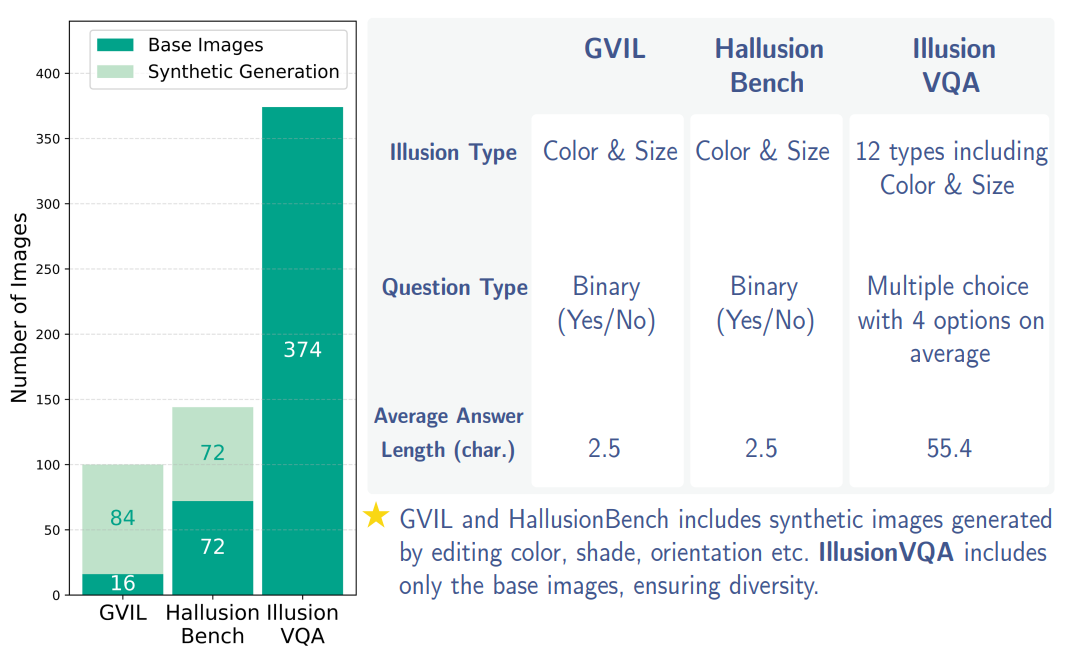 IllusionVQA
with prior illusion datasets -
GVIL and
Hallusion-Bench.
IllusionVQA
with prior illusion datasets -
GVIL and
Hallusion-Bench.
@inproceedings{shahgir2024illusionvqa,
title={IllusionVQA: A Challenging Optical Illusion Dataset for Vision Language Models},
author={Haz Sameen Shahgir and Khondker Salman Sayeed and Abhik Bhattacharjee and Wasi Uddin Ahmad and Yue Dong and Rifat Shahriyar},
booktitle={Conference On Language Modeling (COLM)},
year={2024},
organization={COLM 2024}
}